Legacy Faceplate Sale: 25% off VCA and QLFO, 15% off Babel + BX and QMS
On Audio Fidelity: The Concept of Fidelity
Part 1 of 3
“My God,” I cried in horror, “what are you doing,
Mozart? Are you serious about inflicting this monstrosity upon yourself, and
upon me? About subjecting us to this hideous contraption, this triumph of our
time, the final, victorious weapon that our age deploys in its war of
annihilation against art?”…
Thomas
Edison with an early twentieth century phonograph
He regarded my agonies with deep pleasure, he turned the cursed screws,
adjusted the metal cone. Laughing, he continued to let the distorted,
disfigured, and poisoned music seep into the room; laughing he gave me my
answer.
“No pathos, please, dear neighbor! By the way, did you notice the
ritardando there? A stroke of genius, no? Ah yes, and now, you impatient man,
let the spirit of that ritardando sink in—do you hear the basses? They
stride along like gods—and let old Handel’s stroke of genius penetrate
and calm your restless heart! Listen without pathos and without mockery, my
little man, and behind the veil of this ridiculous contraption—which
really is hopelessly idiotic—you will hear the distant figure of that
godly music passing by!…Observe this absurd metal cone, it seems to be
doing the stupidest, most useless, most forbidden thing in the world, just
taking music that’s being played in one place and indiscriminately blasting it
into another place where it doesn’t belong—stupidly, crudely, and
miserably distorted, too—and nevertheless it can’t destroy the
original spirit of that music, all it can do is use that music to demonstrate
the helplessness of its own technology, the mindlessness of its mechanical
operations!”
—Herman Hesse, Steppenwolf, 1929.
Audio fidelity is a fantasy, not a reality. But it is a fantasy that can
show us true things about the world—and like all fantasies, it contains
a utopian impulse, a dream about hearing that manifests in an unfolding
future.
The idea of “fidelity” divides audio enthusiasts into roughly two camps,
both of which blend together large portions of unfounded ideology, subjective
impressions, and pieces of our best current understandings of sound,
electronics, mathematics, psychology, and sound reproduction. Efforts by both
camps have at certain times improved our understanding of sound, hearing, and
electronics, and at other times have impeded progress through attachment to
ideas which later were found to be suspect. On the one side, there are the
scientific skeptics, who generally work with measurements taken by nonhuman
instruments and derived from basic engineering principles. Although the
analogy is far from perfect, let’s call this Camp Skully, in reference to
the character from The X-Files. On the other side, there is Camp Mulder, which
works empirically, trusting subjective impressions and distrusting
measurements. While this description of the two camps signals real differences
in approach, like any opposed ideologies each camp is often defined more by its
opinion of the other camp than by its own beliefs. To Camp Skully, Camp Mulder
is at best based on demonstrably unreliable subjective impressions, and at
worst full of con men and rubes. To Camp Mulder, on the one hand Camp Skully
contradicts the very idea that we can experience things and that our
experiences are real, and on the other hand views science as a fixed body of
knowledge instead of an unfolding process of knowledge production. Of course,
neither side is entirely what their opponents believe they are, and neither
side is entirely what they believe themselves to be.
Mulder and
Skully
As electronic musicians, these debates are not addressed to what we do, and
yet they nevertheless surround our musical practice. For example, while
digital recording is not so different from analog recording, digital
synthesis often requires entirely different mathematics that will react very
differently in a complex patch. And yet, searching for information on digital
audio, we will doubtless encounter mostly debates about the merits of digital
and analog in the faithful reproduction of sound, with perhaps a few minor
debates about analog and digital mixers that are sort of relevant to us. In
many ways, our problem as musicians is that the fidelity controversies produce
enough text to overwhelm and heavily color any practical information we might
need. But while these controversies are a problem for us, they nevertheless
also have things to teach us.
This exposition is divided into three parts. This part will cover the big
ideas of fidelity, detailing the usefulness of the idea, but largely focusing
on its problems and limits. The next part will deal with how fidelity is
measured, and what these measurements mean. The last will focus on the
characteristics of digital and analog media.
The Concept of Fidelity
Part of the reason for such wild controversy around fidelity is the
inherent difficulty of defining the concept. From its earliest articulations,
philosophy has been troubled by the way that two different objects can seem to
be copies of the same sort of thing. We are inundated by examples of striking
similarity: two ingots of copper, two sparrows, two pronunciations of the same
word. If these were identical in every respect, they could not actually be two
different objects in the first place. At the very least, they differ in
location, time, matter, and relation, but practically there are always many
more differences. Platonic and Aristotelian philosophy thinks about this by
imagining some perfect, single, conceptual form for a type of thing,
shaping many objects like a single brass stamp can shape many wax seals.
Today, nobody much likes this weird concept of perfect forms, but its not as
though we have solutions that are so much better. Physics has very little to
say about similarity or sameness, focusing instead on mathematical
relationships between measurements. Aristotle made use of the concept of a
form in defining and categorizing animal species—“species”
is in fact the Latin translation of the Greek word for form in
Aristotle’s works. But modern Biology prefers to organize the tree of
life by genetic relationships, rather than similarity.
Practically, there are countless easily measurable differences between any
sound and the best possible reproduction we can make. Some of these
differences are subtle and small, and others are big and obvious. Discussions
about fidelity deal with these differences through the idea of the
difference that doesn’t make a difference, differences that are
less or more important, not important at all, not “part of” sound
at all, differences that it is silly to care about, etc. Camp Mulder often
hangs on to some (nonexistent) absolute fidelity as a limit we must constantly
approach. Camp Skully is more likely to define specific measurements and
thresholds which together define “good enough” or
“indistinguishable” fidelity. But to make any sense at all of the
idea of fidelity, both camps must adopt this idea of a difference that
doesn’t make a difference, and a difference that does
make a difference.
For a musician, the problems with the concept of fidelity start right here
at the beginning. First, when we are actively creating things, what is this
original from which we are supposed to measure differences? Second, why should
any difference not make a difference? Why should we not care, deeply,
about things that others find trivial? One of the many functions of art is to
foreground and highlight differences that others have passed over and
forgotten. Why, for example, shouldn’t it matter whether your instrument
is a material object or only virtual software? The production and materiality
of the art object has been an explicit, central concern for art and music for
at least the last hundred years or so. Hendrix set his guitar on fire, but you
cannot burn a software plugin. Maybe it doesn’t make a difference, and
then maybe it does. Part of what we must do is choose the differences we care
about. And of course, it could just as easily be an artistic goal to create a
sense of separation from materiality that is only possible with software.
Part of what’s at stake here—for all sides, Mulders, Skullys,
and musicians—is the practice of modeling and its relationship to art
and reality. Models are so fundamental to science that one might even say that
scientific knowledge is models. Camp Skully thinks so, although they
think observations are also important. Camp Mulder might think that our
observations are the real knowledge, while models are just things we say. The
worst disagreements about fidelity usually come when someone from Camp Mulder
explains their observations with bad models in which they are not actually
that invested, while someone from Camp Skully dismisses the Mulderite’s
entire subjective experience just because their models don’t make any
sense. For musicians, the problem is that these models are at once
descriptions of how our tools work and assertions about what sound and music
are. While the former is something we need in order to understand our
instruments, the latter is unnecessarily constraining, particularly as debates
about fidelity and studies on fidelity rarely move past a nineteenth century
concept of music, ignoring over a hundred years worth of thought about chance,
space, synaesthesia, movement, noise, context, events, audience, subjectivity,
spirituality, materiality, etc.
Models and understanding are a vital part of our work, but beware when Camp
Skully “explains” what sound is, what music is, and how silly we
are to care about this or that; beware all the more the bad models of Camp
Mulder, or its occasional suggestion to go entirely without models. For
musicians, the difficult philosophical issues of the relationship between
modeled understanding and subjective experience often evaporate, replaced with
a practical requirement to learn how to use a particular device as best as
possible, along with an artistic impulse that was never negotiable.
The Model of Fidelity
Maxell tape
advertisement, 1983. The subjective experience is foregrounded. Also note that,
as exciting as this is, the listener remains perfectly
still. Guy Debord would have a field day.
For both camps, the model of fidelity begins with the subjectivity of a
“normal” human listener. This listener has two ears, and each ear
receives a one dimensional stream of sound, which consists of vibrations in
the air lying within the 20Hz–20kHz range. The ear converts each one
dimensional stream into a spectrum, a
perception of the various loudnesses of different frequencies. The mind then
collects related frequencies into particular, individual sounds, primarily by
matching frequencies to harmonics. Next, it compares the relative loudnesses
of these frequencies in our two ears in order to construct an imaginary two
dimensional image of sound in space. Lastly, the mind observes how these
sounds make reverberations in order to construct a map of the space in which
the sounds are happening. This listener is stationary, looking at the sound as
if they were looking out the window, separate from this sound, neither
actively exploring the space nor participating in the creation of sound.
The sound being heard is abstracted from the medium that actually produces
it—the listener’s audio system and the space in which it operates.
The overall experience is then judged. Classically, any difference between the
listener’s experience and the experience of someone sitting in the
imagined original space would be coloration or distortion, negatively
impacting the fidelity. Recently some people (largely in Camp Mulder) have
argued that the overall quality of the experience and perhaps the
“sense” of realism or presence can actually be enhanced by
intentionally and subtly altering the original sound. However, even in that
minority, virtually nobody can agree on what kinds of changes ought to be
made.
For all the talk of “objective” and “subjective,”
the central disagreement of these two camps is really just whether we should
trust people to know their subjective experience or whether we should trust
scientific researchers to know about people’s subjective experiences.
Both sides do not consider an objective, anti-humanist approach to sound, an
approach that would incorporate existence and possibility, nonhuman, disabled,
or alternate spaces of perception, or the capacity of subjects to interact
with and change the world, instead of simply observing it.
In Approaches to
Sound, I already detailed some of the potential problems and benefits that
come with the psychoacoustic approach. Here, I will address only a few common
models and practices from the fidelity discussions. Like in most scientific
practices, as the findings of psychoacoustics, acoustics, electronics, and
mathematics make their way to non-researchers, the nuance of what is well-known
and what is only suspected tends to disappear, as do variations and margins of
error.
Phase and Space
For the most part, although the fidelity model is limited and inexact (and
this limitation is also what makes it useful), it is not exactly
wrong. There is one aspect, however, which is problematic enough that some
more nuanced models of fidelity are modified to account for it: the complete
absence of phase. For over a century, it has been understood that humans make
use of phase information to understand the position and spatiality of sounds.
We find a sound’s position based not just on relative loudness, but on
which ear receives a sound first. However, our sound reproduction systems
essentially have no hope of accurately reproducing this effect. While
spatialization is a topic unto itself, this section summarizes the central
tenets of spatialization in stereo audio, and explains why most people think
that amplitude, rather than phase, provides spatial cues.
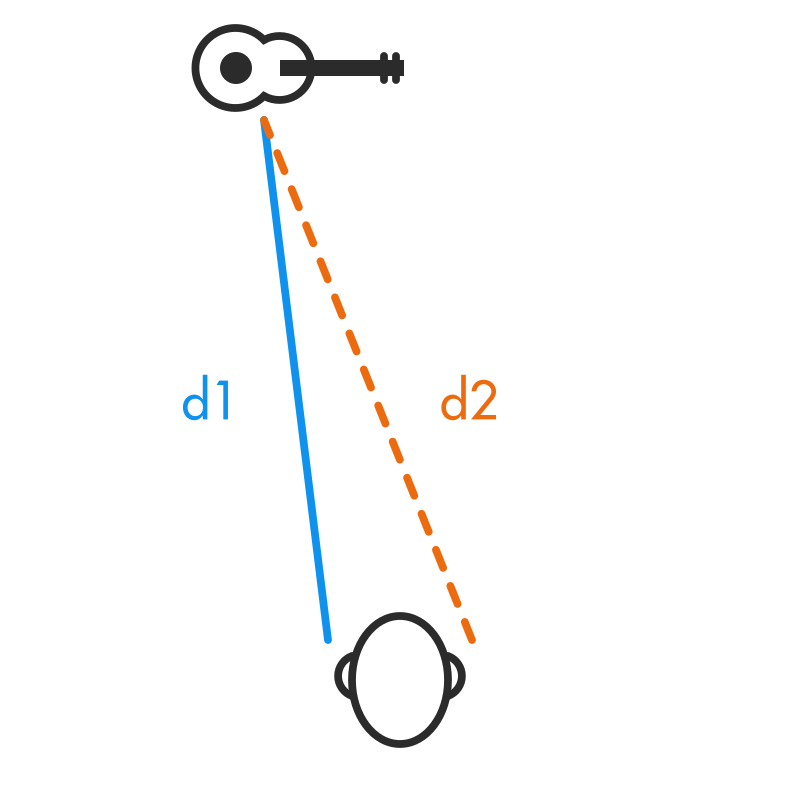
A
sound source will have different distances to each ear, resulting in different
phases.
In the early twentieth century, Lord Rayleigh developed a psychoacoustic
understanding of the way in which human hearing locates a sound source in
space, which was slightly revised and expanded by others’ work on
localization in the 1920s and 30s. A point source emitting a sound will
present different signals to each ear. With the different distances to each
ear, it will take a different amount of time for the sound to travel, and also
the sound might have to get around your head to reach one ear, while being able
to directly reach the other ear. Roughly, we can divide human spatial perception
into three frequency regions. At higher frequencies, with wavelengths nearing
the size of one’s head, the head will function effectively as a filter,
altering the relative amplitude of the sound in each ear. Conversely, the
filtering effect, as well as the small wavelength, means that the phase
difference between one ear and the other will be affected and might not give
good information as to the location of a sound. At lower frequencies (below
around 700Hz), with wavelengths lower than the size of one’s head, not
much filtering will occur, and the two ears will hear with equal loudness.
However, the phase differences resulting from the different distance between
the source and each ear will be preserved, allowing us to infer the direction
of the sound. As the frequency decreases, the same interaural delay will result
in a smaller phase difference, and while experiments have shown an ability to
determine direction down to the bottom of the range of hearing, this becomes
more difficult for frequencies below 60Hz or so. Lastly, very short sounds will
be located not according to a phase difference per se, but according to the
time difference between the arrival of the sound at each ear.
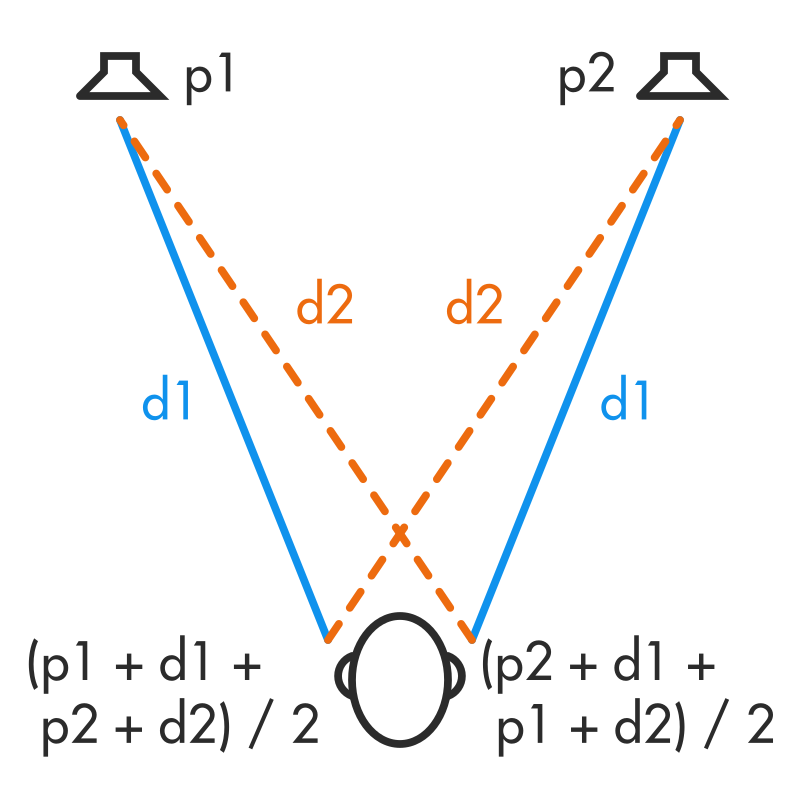
Because the ears hear phase from
both speakers, this phase difference more or less cancels out
completely.
Early attempts at spatial audio tried to use multiple speakers to reproduce
the actual structure of a three-dimensional wall of sound moving toward the
listener. This would be a more objective approach to spatial audio. But
needless to say, this was both difficult and expensive. The much simpler
method was just to reproduce what the listener would have heard, the two
signals to each ear. While this was somewhat possible with headphones, with
two speakers the situation seemed pretty hopeless. Signals from both speakers
would of course reach both ears, and these overlapping signals would add
together to eliminate the recorded phase differences. The problem seemed
intractable.
In 1931, Alan Blumlein created a system to address these difficiencies,
creating the modern concept of stereo. He realized that we can recreate the
required phase differences from scratch by combining sounds in the medium
of the air itself. Because the distance from each speaker to each ear is
different, the sound from each speaker arrives at each ear with a different
phase. As we saw in Phase, Delay, and
Mixing, two sine waves with different phases and different amplitudes will
combine to form a single wave with an intermediate phase that depends on the
relative amplitudes coming from each speaker. If the waves coming from the left
and right speakers have different amplitudes, they will combine to create a
different phase for each ear, as if the sound came from somewhere between the
speakers.
Although this illusion is convincing, the exact pair of signals we would
have heard from a single sound source is not generally reproduced. Panning
with volume creates a phase difference in our ears, but also creates a volume
difference that does not necessarily reproduce what happens when a single
sound travels through the air. (This is partly why there is such controversy
about pan laws, the way panning changes the relative volume of the left and
right channels—there is not actually a correct way to do it.) Further,
for the most part we locate very short sounds (clicks) based on the time
difference in the arrival of the initial wavefront. Relative volume will do
nothing to modify the initial arrival of each wave.
Headphones are much better at controlling the phase information received by
each ear, but unlike speakers they do not convert relative volume into
relative phase. There are algorithms called head related transfer functions
(HRTFs) that can be used to spatialize sounds for headphones, but they are only
rarely used in music production. Nor do a mixer’s panning controls alter
phase. When a recording produced for speakers is played back on headphones, we
receive spatial cues in a strange, otherworldly way. Our ears receive
differences of phase and volume that would not be produced by sounds travelling
through the air. Conversely, a recording produced for headphones will lose
essential phase information and feel flat when played back on speakers.
Ideally, we would produce entirely different mixes for these two media. Given
listening practices, nearly all modern mixes are compromises between these (and
other) media, while older mixes often translate poorly to headphones.
Confusion about the relative nature of phase adds to the perception that
phase does not matter. Absolute phase does not really exist, only the relative
phase between two different waves. Consequently, of course absolute phase is
not perceptible, while absolute frequency and amplitude (which do exist) are
perceptible. In the stereo model, phase differences between the left and right
channel are more or less eliminated, and thus our speakers have already
destroyed what we would otherwise perceive. The only other way phase exists in
these recordings is in phase coherence, the relative phase of
different frequencies in a harmonic sound. Bleeding edge research
indicates that phase coherence might be used to detect the closeness of a
sound, or whether a sound is a reflection or a direct source.
For all these reasons, the stereo model leads to the misconception that
phase is not perceptible, or if phase is perceptible, this is subtle and only
the most capable listeners will notice. In fact, so far as we can tell, all
human binaural listeners generally make use of relative phase information in
discerning the positions of sound in space. It is just that stereo speakers are
very bad at properly reproducing recorded phase. Fortunately, while most
discussions of fidelity don’t fully understand these issues, some do, and
others are nevertheless interested in subtle effects. It is not uncommon for
phase to be a concern for fidelity. Still, it is much more common for phase to
be ignored, or worse, sacrificed, in order to maximize some other measurement,
such as frequency response.
An alternate
history of what stereo could have been
As musicians, we may or may not care about space at all. But if we do care,
we should recognize that space is not something that happens in stereo sound,
quadraphonic sound, or even ambiphonic sound. Space is more than these things,
and every way that sound exists in space cannot be reproduced by these
systems. Conversely, a set of speakers does not have to produce sounds
according to the stereo model, and a room does not have to respond to speakers
according to the stereo model. Often the most interesting spatializations
occur when this model is abandoned and speaker placement and room effects are
driven solely by the overall artistic intent.
The Audio Range
The range of our hearing is limited in frequency. The commonly given range
of 20Hz–20kHz is a surprisingly good approximation for human hearing, but it
doesn’t really reflect how the limits to our hearing work. Our ears detect
sounds at loudnesses which change with frequency. Somewhere above 12kHz, this
threshold starts to rise, and somewhere around 17kHz, this threshold starts to
rise very steeply, then again more gradually after 20kHz. Some studies have
detected hearing at very loud levels above 28kHz. But these upper
thresholds seem to vary pretty wildly between different people, with some able
to hear 20kHz at a loud whisper, and others unable to hear it even at piercing
volumes. A similar thing can be said about the lower end of the audio range.
Here, perhaps, it makes more sense to extend the commonly accepted range down
to 16Hz or lower, as sound tends to have more energy concentrated in the low
end.
Note: I am not advising you to create loud sounds outside of the range of
hearing. Please be very, very cautious with loud sounds that you cannot hear.
They may pass the threshold of hearing damage before they pass the threshold of
hearing. The same exposure levels as for the 20Hz–20kHz range should
apply.
Despite the fact that these limits to hearing are fairly well documented,
the reason for these limits is not completely understood. Bone conduction,
where the inner ear is stimulated by vibrations in the skull, rather than the
air, seems to be able to transmit frequencies up to 120kHz or even 200kHz.
Because of this, some research has theorized that our cilia (the elements of
the ear which transform vibrations to electronic impulses) have a very high
frequency response, but that our ear canal acoustically filters high frequency
sound. Others, however, theorize that high frequencies vibrating through our
bones become lower frequencies through processes of resonance or distortion.
In musical performances with differing media (water rather than air) or
different transducers (bone conduction), frequency limits will be different.
While some studies on this exist, outside of air and speakers, even the range
of hearing is not yet settled.
But the big problem with 20Hz–20kHz isn’t the specific range or
hearing thresholds, but the idea that because we only hear certain
frequencies, we can safely ignore what happens with the other frequencies,
with no effect to “sound.” This is likely to cause problems. High
frequencies might be immediately filtered out by whatever the next stage is,
in which case they have no effect. However, high frequencies will have no
effect not because they wouldn’t affect what we hear, but because, due
to an intentional or accidental feature of the electronics, they are in fact
removed without us thinking about it. Otherwise, frequencies higher and lower
than we can hear can affect our hearing a number of different ways.
First, when high frequencies excite a speaker, they will contribute to audible
distortion. They may do this in other electronic systems as well. This is known
as intermodulation distortion, or IMD. In theory, with a completely linear
system, high frequencies and low frequencies do not affect each other. But in
practice, these frequencies ride together through systems with limits and
slight curves, especially the motion of the speaker itself, and different
ranges of frequencies have slight effects on each other. Since distortion is
always present to some degree in all systems, a high frequency contribution is
not necessarily a bad thing, so long as these high frequencies correspond to
musical content. Of course, deliberately producing audible distortion by
running high frequencies against limits and curves is also possible.
Second, in musical uses, frequencies do not necessarily stay where they
originate. A sampler, for example, might pitch a sound recorded at 2kHz to 20Hz
instead. In this case, the high frequency harmonic content at the upper 20Hz
limit will be the original frequency content at 2MHz, shifting the entire AM
radio band into the audible spectrum. More likely, a frequency this high does
not exist in the 2kHz recording, and the sampler would sound dark when pushed
to these limits. But other mechanisms for shifting frequency ranges, such as
modulation or frequency shifting, might preserve frequencies this high.
Third, as noted in the post on Spectra, the
decomposition of a sound into individual frequencies is an analytic tool, not
a fact about the sound itself. In the lower frequencies in particular, rhythm
and frequency are two different ways of looking at the same thing; phase and
timing are two different ways of looking at the same thing; and the phase
differences created through filtering these low frequencies can affect the
clarity ond definition of a given rhythm. 10Hz, for example, is the same as
16th notes played at 150bpm.
The reality is that, although we may be limited by our bodies and our
tools, there is no freqency that is wholly irrelevant. All frequencies are
a part of sound, without exception, and we can create ways to use them in
our music.
Snake Oil, and Other Stories about Hearing
The label for snake oil
In the late nineteenth century, Clark Stanley began travelling around the
United States selling rattlesnake oil as a cure-all. He made numerous claims
of its effectiveness, mostly focusing on pain and arthritic relief. In 1893,
he presented his product at the Chicago World’s fair, and shortly after
went into mass production. Unfortunately for Stanley, in 1917 his product was
found to contain no actual snake oil, leading to widespread outrage. Stanley
was charged a modest fine, and the whole affair was a huge publicity win for
the recently established food and drug administration (FDA), now able to
protect the credulous public from being duped by unvetted medical claims.
Snake oil has become a parable for the suggestibility of the public, the
untrustworthiness of subjective impressions, and the lies and chaos that wait
just beyond the scientific establishment. However, when we take a closer look,
the story is not so simple. While Stanley clearly fabricated a complicated lie
to sell a product, while people believed him, and while the product as stated
had no real research showing its effectiveness, this does not necessarily
indicate that his actual product was ineffective. According to the 1917 lab
analysis, Stanley’s “snake oil” actually contained mineral
oil and tallow along with red pepper, turpentine, and camphor. Camphor and
capsaicin, the key compound in cayenne, are now known to relieve pain and
inflammation, and are ingredients in a number of FDA approved over the counter
pain relief medications. Turpentine is a counterirritant common in liniments at
the time. In short, Stanley’s snake oil contained a very plausible list
of ingredients for an effective liniment. Snake oil wasn’t made of snake
oil, but the public’s perceptions of its efficacy is likely to have been
mostly correct. The public was only duped about the reasons, or the models,
behind these perceptions.
Nevertheless, the idea has persisted that our perceptions themselves can be
fabricated by con men, almost without limit. This poses a problem for
discussions about fidelity, as the entire model of audio fidelity is based
around perceived sound, rather than objective sound. One solution is to create
models of human hearing, and then abstractly apply these models in order to
“objectively” determine what someone would perceive. This
is often done. However, a cursory look at actual psychoacoustic research will
show that generally these models come from first creating a sound and then
simply asking people directed questions about what they hear. We don’t
have magical models of subjective experience that are somehow untainted by
subjective experience.
At some point, even the most skeptical member of Camp Skully needs to
explore what happens when a human hears some particular sound system. In a
misunderstood analogy with medicine, Camp Skully has devised a listening
ritual which tries to eliminate the false snake oil perceptions to which we
are supposedly prone. In this ritual, participants gather together and listen
to complete systems without actually knowing what systems they are listening
to. Then they choose which system they prefer, and in a big reveal that
surprises no one, it turns out that money sort of corresponds to quality but
also sort of it doesn’t. In a different version, participants just try
to reliably identify one system over another. If they can’t do so, then
their perception that one system is better is regarded as an illusion not
based on hearing. To be fair, many participants in these rituals don’t
take them that seriously. But some do.
While I haven’t seen a statistical study, I suspect relatively few
members of the fidelity community have participated in anything like this.
Instead, they receive this ritual as a myth—in such and such a
comparison no one was able to tell the difference. This ritual and myth
together form the narrative basis for the difference that doesn’t
make a difference, the difference that we can ignore in order to preserve
the concept of fidelity. The idea of snake oil, then, usually functions as an
attempt to force social cohesion through the (often politely implicit) shame
and ridicule of supposedly being a con man or a rube.
This ritual contains a model of perception, separate from psychoacoustic
(or even psychological) research. The fidelity listener is exceptionally
astute, able to take in the sound as a whole, remember it as a whole, and then
accurately, mentally compare it a few moments later. For the fidelity
listener, perception is total and passive, and there is no distance between
what we can hear and what we can identify. For this listener, active attention
is not a part of hearing, or at least attention can be retroactively applied
in memory alone. On the one hand, this listener is infinitely suggestible,
hearing anything snake oil salesmen tell them to hear. On the other hand, this
listener is the perfect Cartesian subject, with a direct and reliable
connection between perception and knowledge.
The proponents of this ritual have intentionally designed it to be
stringent, to throw out all but the best information. However, the stringency
of the test isn’t actually biased towards an inconclusive result, but
towards a negative result, towards the difference that doesn’t make a
difference. Consequently, this ritual gives us the idea of a relatively
incapable listener, and a relatively good system of sonic reproduction. One
might contemplate the way that this bias helps the purveyors of hi-fi
equipment sell to Camp Skully.
In contrast, in addition to the limits of our hearing, actual
psychoacoustic research continually discovers new ways in which human hearing
is incredibly good. Certainly our hearing itself is a whole lot better than
our capacity to recall and consciously analyze what we hear. Conversely, while
there are some parts of audio reproduction systems that might be approaching
the threshold of imperceptible differences—well-designed line-level
preamps, for example—our systems as a whole are not even close to this
ideal, even if we adopt the limiting notion of a perfect listening room and a
completely passive listener.
Recordings and Dreams
Everything in our world is constrained by the arrow of time and the
separation of space. Something about sound, in particular, seems to accentuate
our sense of the ephemerality of experience. But recording promises us
something else, and to a certain extent, it actually delivers on this promise.
Recorded sound means that otherwise ephemeral experiences can be repeated,
over decades and continents. At this point in time, it is almost unthinkable
to make music without being immersed in a history of recording over a hundred
years long, filled with dead voices, distant cultures, and passed moments. But
what can we really replicate? And what disappears and is lost forever?
These are the stakes of fidelity. Knowing we will fail, the proponents of
fidelity nevertheless insist that we should have it all, that we
should lose nothing, forever. And why shouldn’t they demand this? To
outsiders, those who seek fidelity often seem weirdly fussy. There they are,
sitting with $10,000 amplifiers cobbled together from tubes, carefully paired
with speakers the size of an apartment, tuning their rooms and talking
constantly about sound, not music. Surely, they must be satisfied? But
instead, they trade in their equipment for things double the cost. They start
messing with things that seem tangential and inconsequential. They buy silver
cables and build granite platforms. Fussy, at best. But to these audiophiles,
these systems are not a means to observe the form of music; they are an
incantation to conjure the presence of sound. They want sound to be here,
really here—not a shoddy reproduction, but a resurrection.
To whoever is not obsessed, obsession seems like a good way to forget about
what really matters. To whoever is obsessed, obsession is the only thing
preventing us from losing something forever. There is not a way to stand above
this and decide who is right. As musicians, we are free to take on audiophile
obsessions, or to leave them aside, either way—we certainly have enough
obsessions of our own. But we should learn from these concerns. To some people,
sound is going to be sacred. To some people, sound isn’t just a thing we
hear, but a future we desire.
References
The opening Hesse quote is from a brand new translation of Steppenwolf from Kurt
Beals.
The X-Files captured a particular moment (1990s) of our culture’s
thoughts about science and its limits (specifically in The States, but not so
different in many other places). The analogy here works best with the first
season, which emphasized the inevitable role of desire in shaping all belief,
without dismissing the importance of evidence. In subsequent seasons, the
first season’s motto “I want to believe” was replaced with
“the truth is out there” and the focus slowly shifted to a gradual
and unending unraveling of conspiracies and anomolies that was much friendlier
to the multiseason TV format.
There are of course multiple differences between analog and digital
technologies. The biggest difference one is likely to encounter in synthesis
is whether the frequency domain is circular (there is aliasing) or linear
(there is infinity). I’ll look at this a little in part 3.
The notion of forms suffuses the entire philosophy of Plato and Aristotle,
not just one part. To get a better idea of what this is, first read the
Wikipedia page on the theory of forms. Then if you want more
probably the best thing to read would be the Phaedo or maybe the
Republic (or if you want the weirdest version, the Timaeus).
For Aristotle, it’s not a bad idea to start with the same thing medieval
philosophers used, Porphyry’s Isagoge i.e. Introduction,
followed by the Categories and maybe the Physics. In modern
philosophy, some touchstones on similarity, identity, and difference are
Fichte, Hegel, Frege, or more recently, Saul Kripke. The way that identity
plays out in mechanical reproduction is often touched on with discussions of
simulacra—copies without an original. Here you might reference
Baudrillard’s Simulacra and Simulation or Benjamin’s
“The Work of Art in the Age of Mechanical Reproduction.”
Physics doesn’t say much about similarity and identity, but what
physics does say ends up being just as weird as Plato or Aristotle.
See, for example, the one-electron
universe theory.
The idea of a difference that doesn’t make a difference is
modeled on a remark by Gregory Bateson that “what we mean by
information—the elementary unit of information—is a difference
which makes a difference” See “Form, Substance and
Difference,” accessible free in a few places through a web search.
Clearly, one could write an entire treatise on the relationship between
perception, information, and difference, but here I only mean to be a little
evocative of what that treatise might look like.
The passive consumption of media is heavily critiqued in Guy Debord’s
The Society of the Spectacle, but Debord focuses primarily on visual
media.
Alan Blumlein’s 1931 patent on stereo sound makes interesting reading.
There are a number of techniques he suggests that are still not widely known or
used. See UK Patent no. 394325.
For more information on phase coherence and its relationship to the
perception of proximity, see David Griesinger, “Phase Coherence as a Measure of Acoustic
Quality” on akutek.info (2010). Griesinger is the engineer most
responsible for the Lexicon 224 reverb.
Spatial audio is a topic unto itself, and I might address it at some point.
I am most interested in non-traditional approaches (vs stereo, quad, 5.1,
etc.). For more on this, see the
manual
for the Quad Mid Side. Michael Gerzon has also done some interesting work
that I’m only just now starting to digest.
Speculation about the potential effectiveness of snake oil can be found
here and there on the web, mostly in special-interest journalism, for example
Cynthia Graber Snake Oil Salesmen Were on to Something in
Scientific American (2007). I have been so far unsuccessful at tracing down a
source in history or anthropology of medicine, if there is one. The
journalistic articles are nevertheless convincing, and cite actual medical
research. The best credentialed source I have seen discussing this is Robert W.
Baloh, Initial Management of Sciatica in Sciatica
and Chronic Pain (2018).